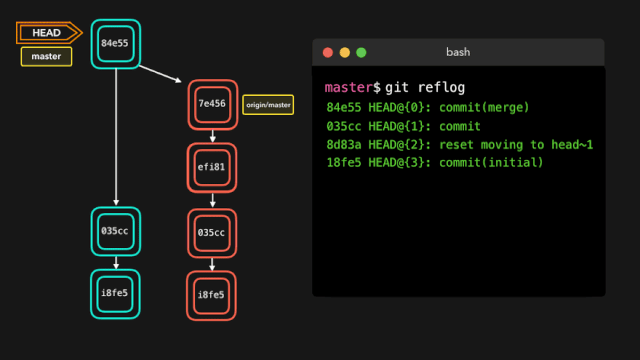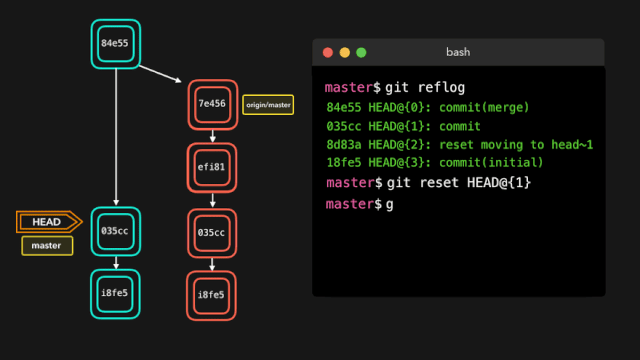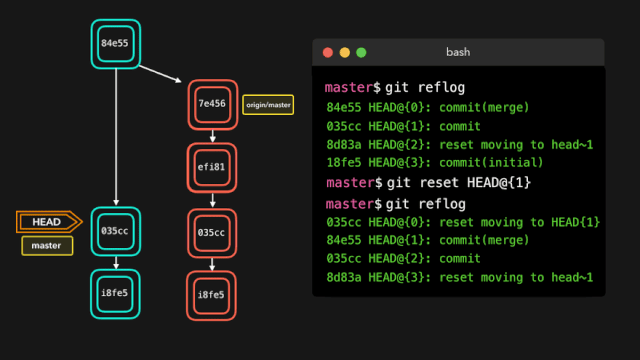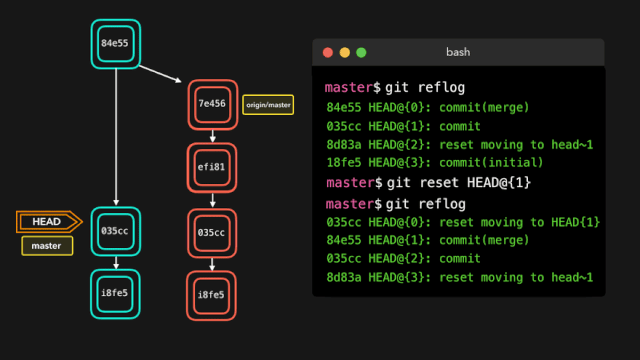
故事开始
在一家IT企业中,项目经理虎大力(龙套) 正在指挥 程序员鹿小明(精英龙套)开发一个大型的增删改查项目。为了开发这个项目。项目组仅有的程序员鹿小明每天工作996
故事进入 V1.0 环节
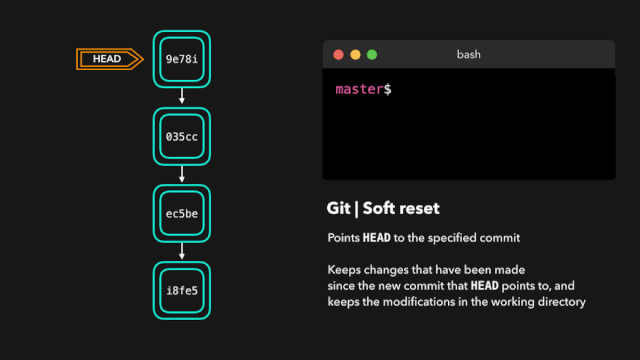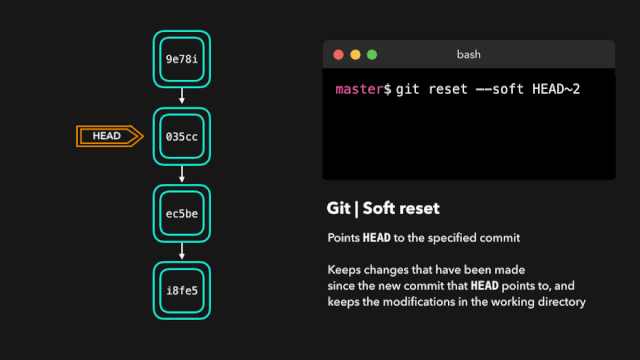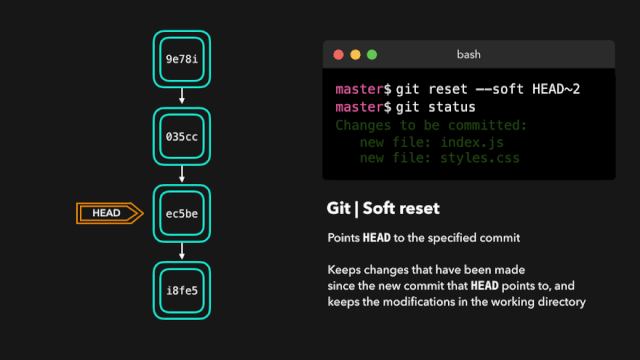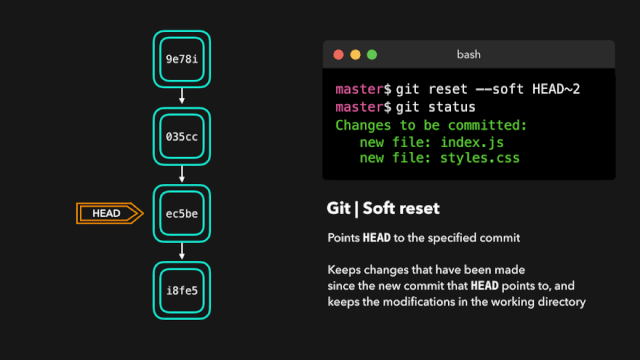
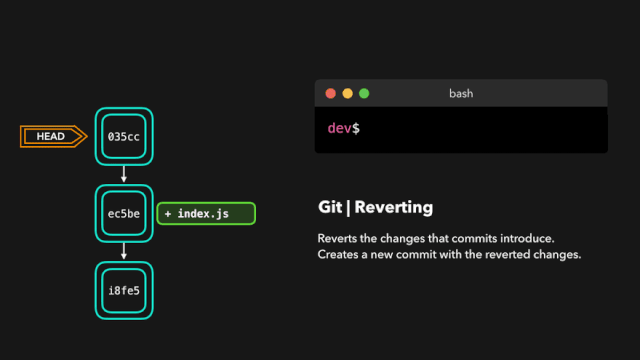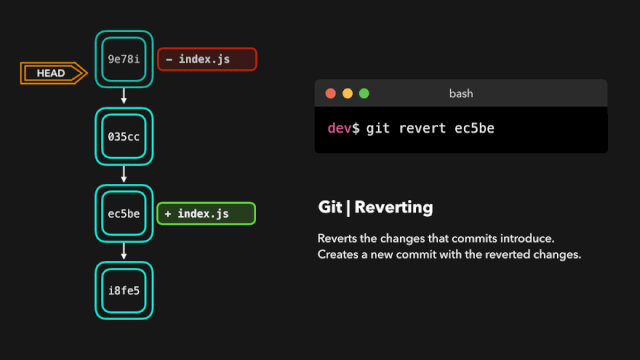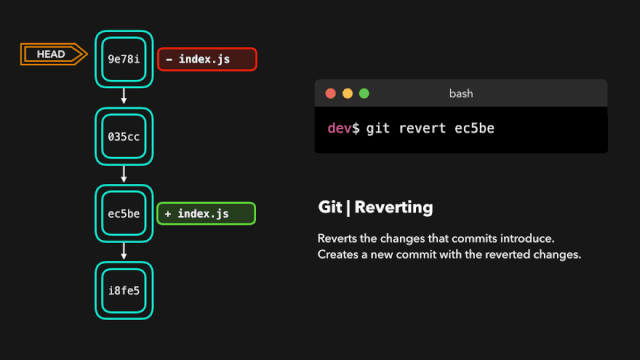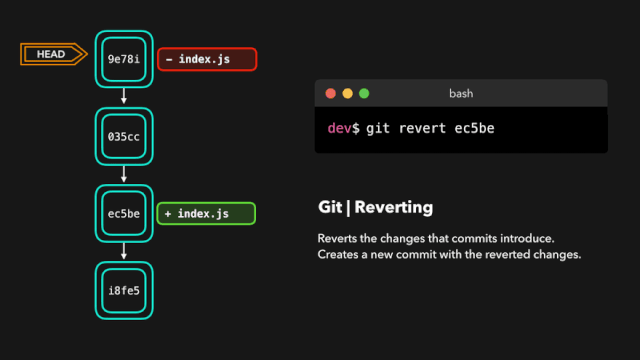
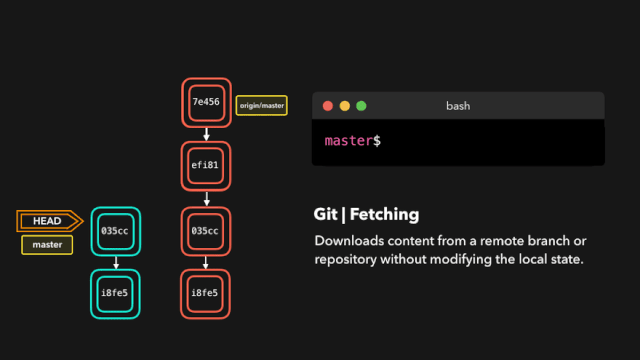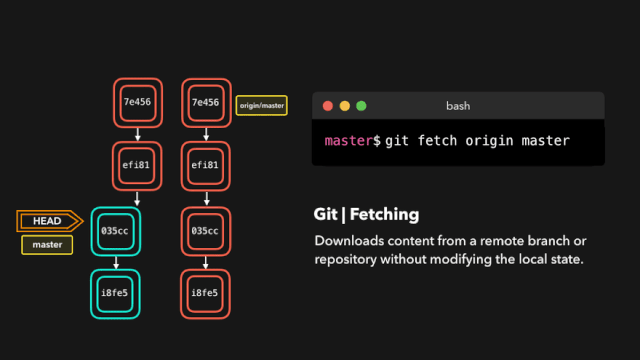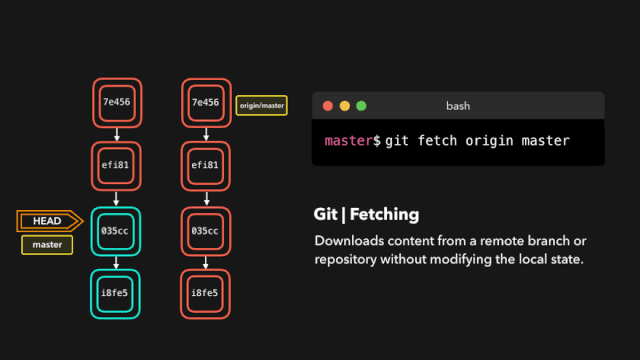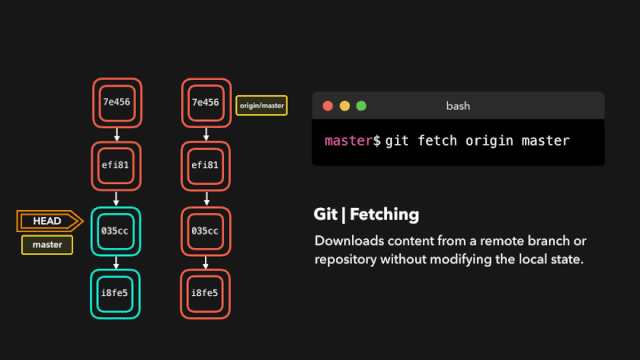
one day,虎大力给鹿小明提出来一个新的需求,为了更好的进行公司的信息化建设,虎大力想要看到代码执行的情况,执行到某个业务的时候在控制台有所表示,例如:执行到查询方法的时候,需要在控制台上出现,这是一个打印方法的信息。

鹿小明一想,这好办啊,本来自己为了调试测试方便就写过很多打印语句,现在无非更多而已。于是就加班加点在所有的增删改查方法中都写了System.out.println()打印语句。顺利完成了这个工作。

故事进入 V2.0 环节
一段时间岁月静好
one day,虎大力找到鹿小明:你这个代码里面System.out.println()太多了,我需要你做成,测试时候显示,上线之后不显示。你去搞一下。
鹿小明于是冥思苦想:我要不要上线的时候把打印语句注释掉,测试的时候再打开呢?
但是想到要经常开关注释也不是个容易的事儿,于是鹿小明一咬牙,996变007,废寝忘食的更新出了 V2.0版本。他把日志打印封装成框架 logging-1.0.jar,可以进行统一的开关。顺利完成了这个工作。
故事进入 V3.0 环节
一段时间岁月静好
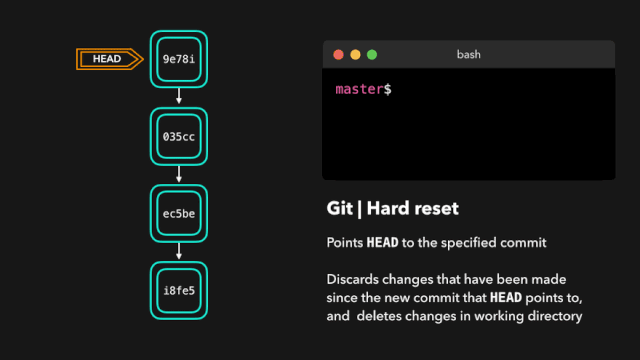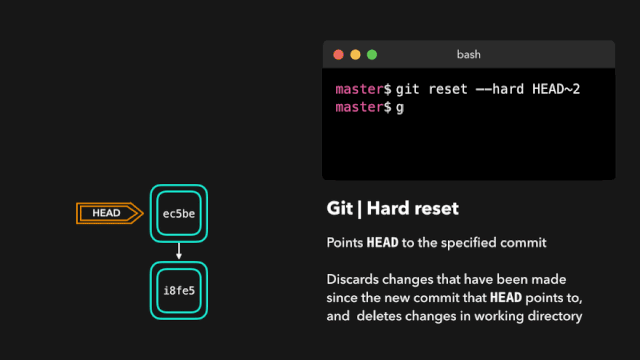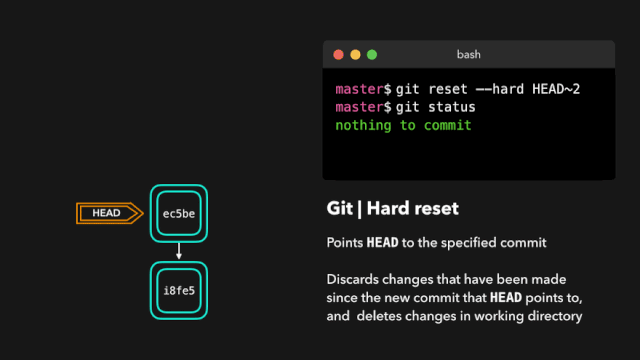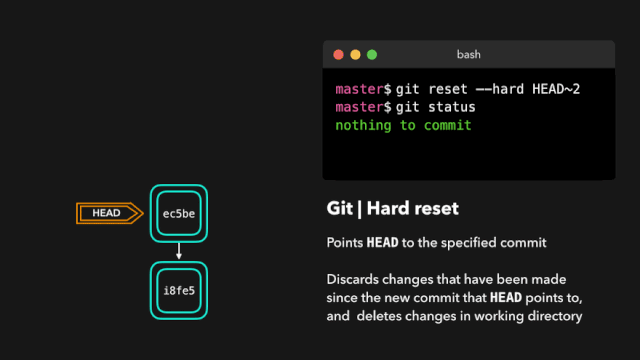
one day,虎大力找到鹿小明:你这个日志框架功能太简单了 ,再搞点新功能,像输出到文件啊,异步啊都搞上。
鹿小明于是冥思苦想,007之后继续007,废寝忘食的更新出了 V3.0 版本,封装成一个新的框架logging-2.0.jar。顺利完成了这个工作。
故事进入 V4.0 环节
一段时间岁月静好
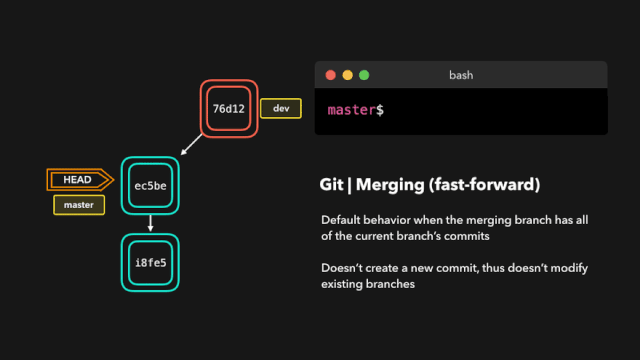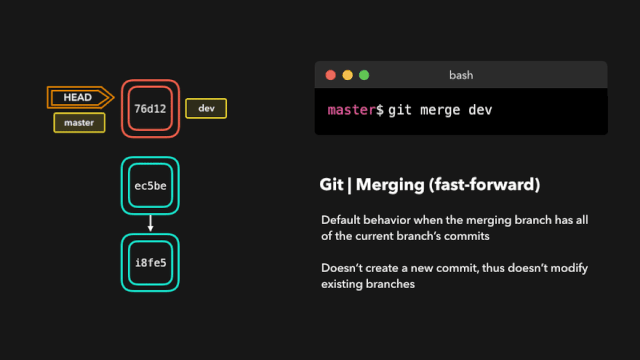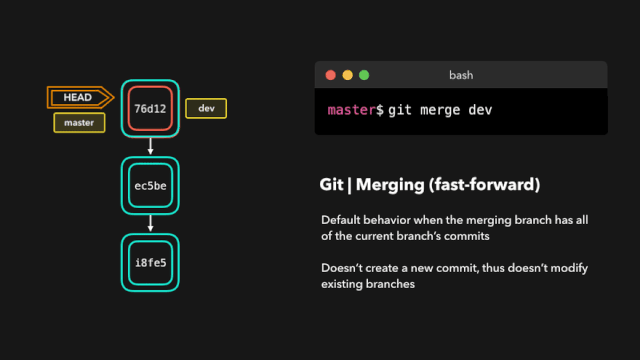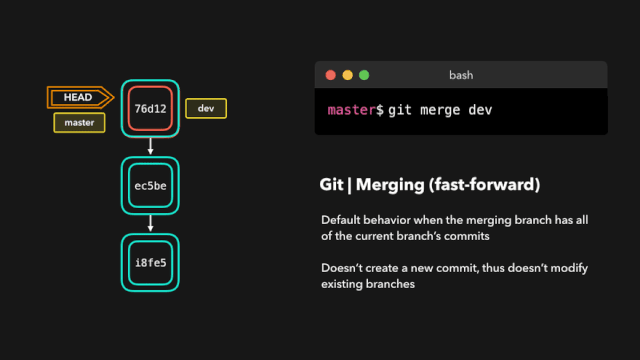
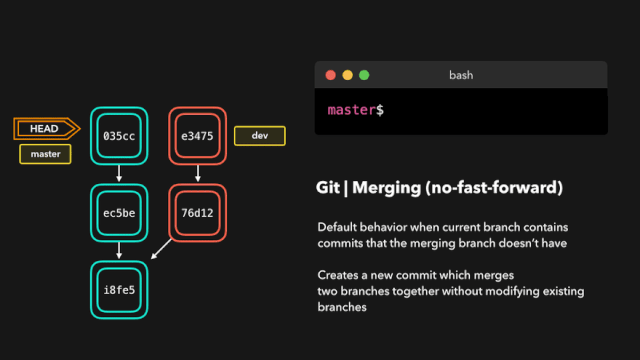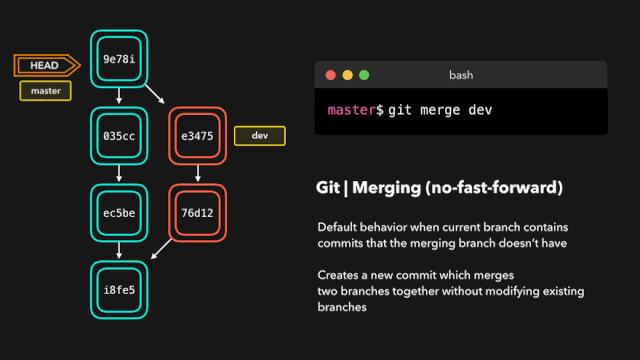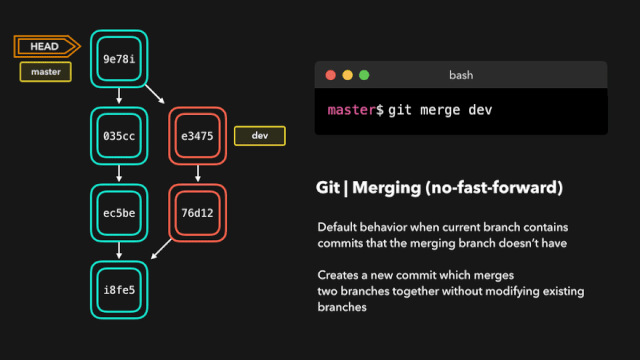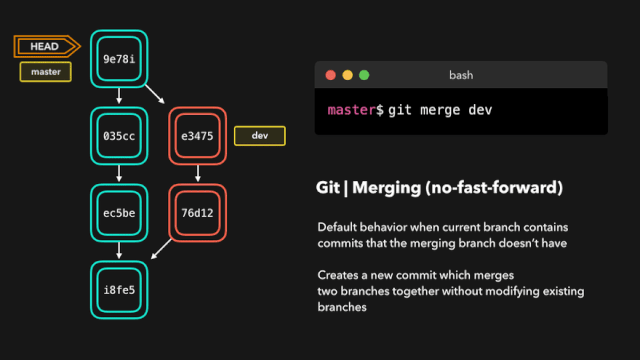
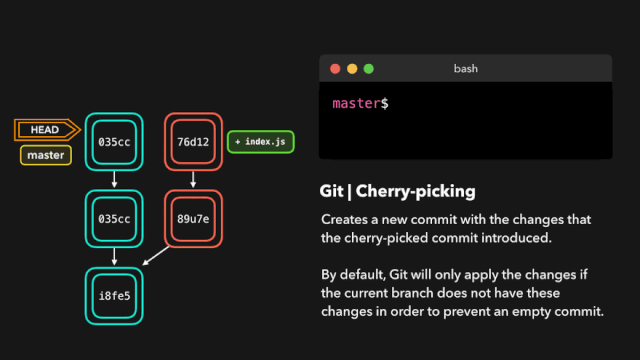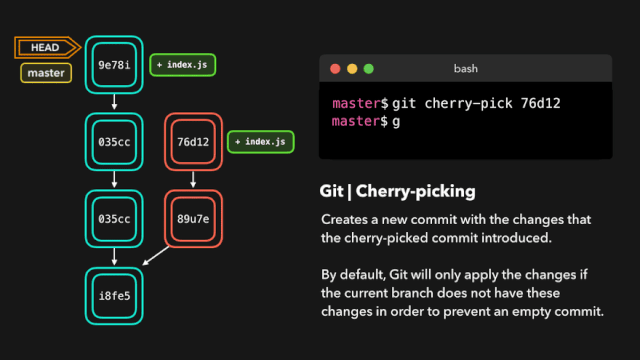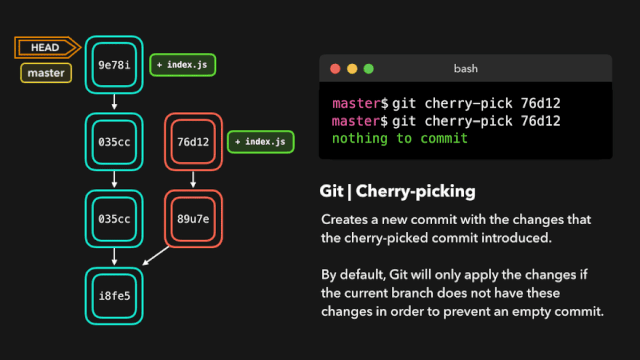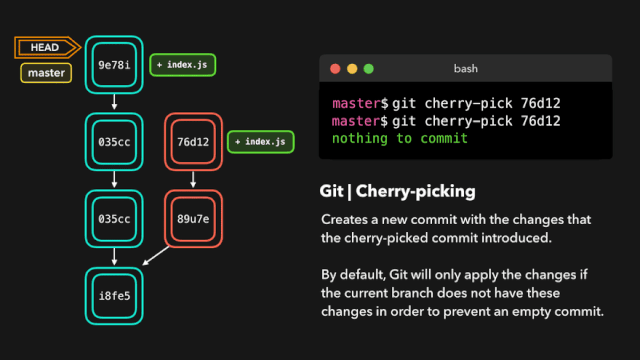
one day,虎大力找到鹿小明:1.0和2.0的api不一样,1.0换成2.0,2.0换成1.0 每次切换都要改代码,你改一下吧,改成可以想用哪个用哪个的。
鹿小明于是冥思苦想,007之后继续007,这个需求有点难,他从JDBC上找到了灵感,JDBC通过统一接口实现了驱动的切换,日志也可以。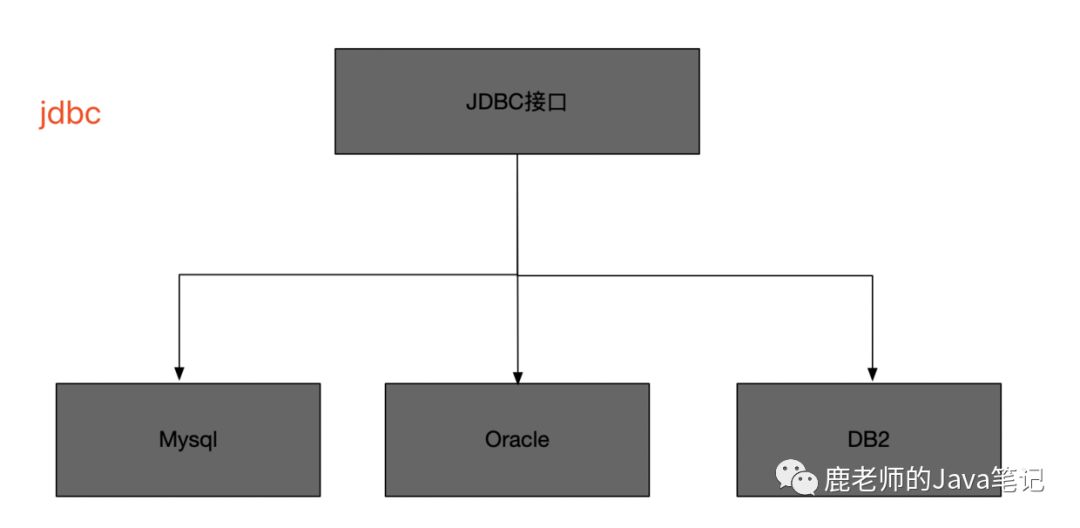
于是,他爆肝搞出来一个日志接口层(日志门面),让 1.0 和 2.0的日志框架都实现这个接口,这样想用1.0的时候就导入1.0,想用2.0的时候就导入2.0 。顺利完成了这个任务。

而这个设计的结构也是现在主流日志框架:log4j logback log4j2 等的结构
| 日志门面(接口) |
日志实现 |
| SLF4J,commons-logging |
Logback,Log4j |
通过它们就打印出了我们常见的各种日志信息
日志框架结构分析
日志框架实际上分为三个部分,除了上面提到的日志门面(接口)和日志库(实现),还有日志适配器
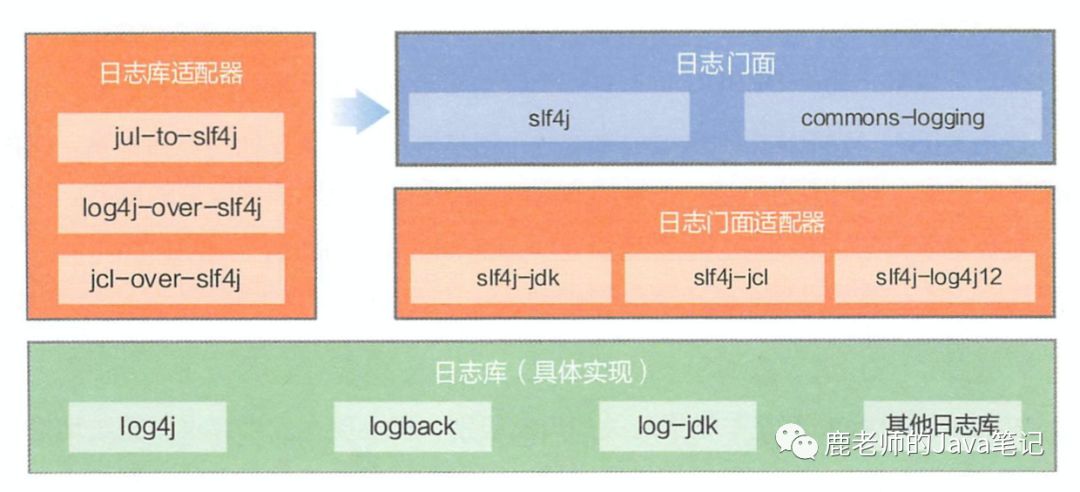
日志门面 接口规范
定义接口规范,不负责具体实现,也就是说以后代码中打印日志时调用的日志门面接口的方法。常见的有 SLF4J,commons-logging 都是这样。常见的日志门面有下面几种
| 日志门面(接口规范层) |
简介 |
| JCL(Jakarta Commons Logging) |
这个jar就是常见的 commons-logging.jar,也是Spring框架中使用的日志门面。由于上一次更新还是在2014年,所以不建议使用 |
| SLF4j(Simple Logging Facade for Java) |
这个jar可以说是最常用的日志jar包了 |
| jboss-logging |
使用最少,一些特定的框架在使用 |
根据简单的分析,在我们的代码中如果要选择一款 日志的接口规范的话,毫无疑问,只有 SLF4j 配得上我们的项目。
日志库 代码实现
日志库是日志功能的具体实现,早期就是为了替代 System.out 语句而出现的。常用的日志库如下:
| 日志库(日志实现) |
简介 |
| log4j |
最早诞生,用的也最多 |
| logback |
最晚出现,和log4j同一作者,是log4j的升级版 |
| log-jdk |
jdk 在1.4版本出现的java.util.logging 简称 log-jdk |
在实际的开发中,log4j和logback的使用都非常的广泛,但是如果你现在要开发的是一个新项目,那么推荐使用 logback