缓存
维基百科
高速缓存(英语:cache,/kæʃ/ kash)简称缓存,原始意义是指访问速度比一般随机存取存储器(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。
如今缓存的概念已被扩充,不仅在CPU和主内存之间有Cache,而且在内存和硬盘之间也有Cache(磁盘缓存),乃至在硬盘与网络之间也有某种意义上的Cache──称为Internet临时文件夹或网络内容缓存等。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为Cache。
缓存特征
缓存也是一个数据模型对象,那么必然有它的一些特征:
命中率
命中率=返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。
最大元素(或最大空间)
缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
清空策略
如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存清空策略来处理,设计适合自身数据特征的清空策略能有效提升命中率。常见的一般策略有:
FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used)
最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
除此之外,还有一些简单策略比如:
- 根据过期时间判断,清理过期时间最长的元素;
- 根据过期时间判断,清理最近要过期的元素;
- 随机清理;
- 根据关键字(或元素内容)长短清理等。
缓存介质
虽然从硬件介质上来看,无非就是内存和硬盘两种,但从技术上,可以分成内存、硬盘文件、数据库。
- 内存:将缓存存储于内存中是最快的选择,无需额外的I/O开销,但是内存的缺点是没有持久化落地物理磁盘,一旦应用异常break down而重新启动,数据很难或者无法复原。
- 硬盘:一般来说,很多缓存框架会结合使用内存和硬盘,在内存分配空间满了或是在异常的情况下,可以被动或主动的将内存空间数据持久化到硬盘中,达到释放空间或备份数据的目的。
- 数据库:前面有提到,增加缓存的策略的目的之一就是为了减少数据库的I/O压力。现在使用数据库做缓存介质是不是又回到了老问题上了?其实,数据库也有很多种类型,像那些不支持SQL,只是简单的key-value存储结构的特殊数据库(如BerkeleyDB和Redis),响应速度和吞吐量都远远高于我们常用的关系型数据库等。
缓存分类和应用场景
缓存有各类特征,而且有不同介质的区别,那么实际工程中我们怎么去对缓存分类呢?在目前的应用服务框架中,比较常见的,时根据缓存雨应用的藕合度,分为local cache(本地缓存)和remote cache(分布式缓存):
- 本地缓存:指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适;同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
- 分布式缓存:指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
目前各种类型的缓存都活跃在成千上万的应用服务中,还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。缓存的使用是程序员、架构师的必备技能,好的程序员能根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
本地缓存
编程直接实现缓存
个别场景下,我们只需要简单的缓存数据的功能,而无需关注更多存取、清空策略等深入的特性时,直接编程实现缓存则是最便捷和高效的。
a. 成员变量或局部变量实现
简单代码示例如下:
1 | package com.thunisoft.local; |
以局部变量map结构缓存部分业务数据,减少频繁的重复数据库I/O操作。缺点仅限于类的自身作用域内,类间无法共享缓存。
b. 静态变量实现
最常用的单例实现静态资源缓存,代码示例如下:
1 | public class CityUtils { |
业务中常用的配置信息,通过静态变量一次获取缓存内存中,减少频繁的I/O读取,静态变量实现类间可共享,进程内可共享,缓存的实时性稍差。
这类缓存实现,优点是能直接在heap区内读写,最快也最方便;缺点同样是受heap区域影响,缓存的数据量非常有限,同时缓存时间受GC影响。主要满足单机场景下的小数据量缓存需求,同时对缓存数据的变更无需太敏感感知,如上一般配置管理、基础静态数据等场景。
Ehcache
Ehcache是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,是一个非常轻量级的缓存实现,我们常用的Hibernate里面就集成了相关缓存功能。
Ehcache
Ehcache是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,是一个非常轻量级的缓存实现,我们常用的Hibernate里面就集成了相关缓存功能。
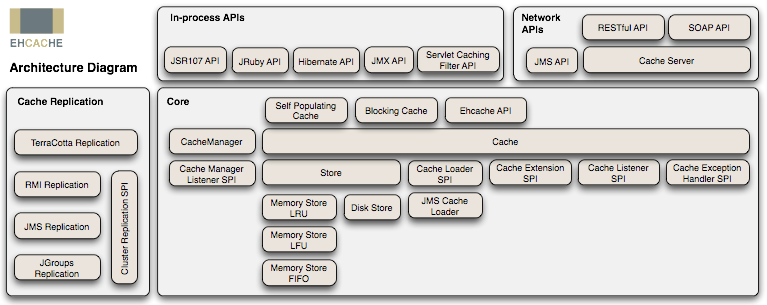
图3 Ehcache框架图
从图3中我们可以了解到,Ehcache的核心定义主要包括:
- cache manager:缓存管理器,以前是只允许单例的,不过现在也可以多实例了。
- cache:缓存管理器内可以放置若干cache,存放数据的实质,所有cache都实现了Ehcache接口,这是一个真正使用的缓存实例;通过缓存管理器的模式,可以在单个应用中轻松隔离多个缓存实例,独立服务于不同业务场景需求,缓存数据物理隔离,同时需要时又可共享使用。
- element:单条缓存数据的组成单位。
- system of record(SOR):可以取到真实数据的组件,可以是真正的业务逻辑、外部接口调用、存放真实数据的数据库等,缓存就是从SOR中读取或者写入到SOR中去的。
在上层可以看到,整个Ehcache提供了对JSR、JMX等的标准支持,能够较好的兼容和移植,同时对各类对象有较完善的监控管理机制。它的缓存介质涵盖堆内存(heap)、堆外内存(BigMemory商用版本支持)和磁盘,各介质可独立设置属性和策略。Ehcache最初是独立的本地缓存框架组件,在后期的发展中,结合Terracotta服务阵列模型,可以支持分布式缓存集群,主要有RMI、JGroups、JMS和Cache Server等传播方式进行节点间通信,如图3的左侧部分描述。
整体数据流转包括这样几类行为:
- Flush:缓存条目向低层次移动。
- Fault:从低层拷贝一个对象到高层。在获取缓存的过程中,某一层发现自己的该缓存条目已经失效,就触发了Fault行为。
- Eviction:把缓存条目除去。
- Expiration:失效状态。
- Pinning:强制缓存条目保持在某一层。
图4反映了数据在各个层之间的流转,同时也体现了各层数据的一个生命周期。
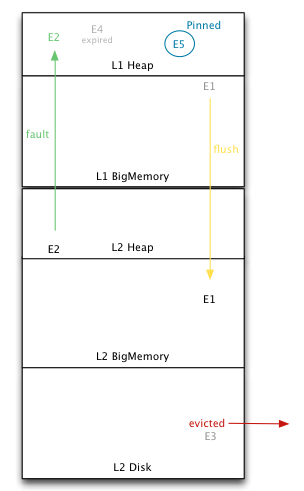
图4 缓存数据流转图(L1:本地内存层;L2:Terracotta服务节点层)
Ehcache的配置使用如下:
1 | <ehcache> |
整体上看,Ehcache的使用还是相对简单便捷的,提供了完整的各类API接口。需要注意的是,虽然Ehcache支持磁盘的持久化,但是由于存在两级缓存介质,在一级内存中的缓存,如果没有主动的刷入磁盘持久化的话,在应用异常down机等情形下,依然会出现缓存数据丢失,为此可以根据需要将缓存刷到磁盘,将缓存条目刷到磁盘的操作可以通过cache.flush()方法来执行,需要注意的是,对于对象的磁盘写入,前提是要将对象进行序列化。
主要特性:
- 快速,针对大型高并发系统场景,Ehcache的多线程机制有相应的优化改善。
- 简单,很小的jar包,简单配置就可直接使用,单机场景下无需过多的其他服务依赖。
- 支持多种的缓存策略,灵活。
- 缓存数据有两级:内存和磁盘,与一般的本地内存缓存相比,有了磁盘的存储空间,将可以支持更大量的数据缓存需求。
- 具有缓存和缓存管理器的侦听接口,能更简单方便的进行缓存实例的监控管理。
- 支持多缓存管理器实例,以及一个实例的多个缓存区域。
注意:Ehcache的超时设置主要是针对整个cache实例设置整体的超时策略,而没有较好的处理针对单独的key的个性的超时设置(有策略设置,但是比较复杂,就不描述了),因此,在使用中要注意过期失效的缓存元素无法被GC回收,时间越长缓存越多,内存占用也就越大,内存泄露的概率也越大。
Guava Cache
Guava Cache是Google开源的Java重用工具集库Guava里的一款缓存工具,其主要实现的缓存功能有:
- 自动将entry节点加载进缓存结构中;
- 当缓存的数据超过设置的最大值时,使用LRU算法移除;
- 具备根据entry节点上次被访问或者写入时间计算它的过期机制;
- 缓存的key被封装在WeakReference引用内;
- 缓存的Value被封装在WeakReference或SoftReference引用内;
- 统计缓存使用过程中命中率、异常率、未命中率等统计数据。
Guava Cache的架构设计灵感来源于ConcurrentHashMap,我们前面也提到过,简单场景下可以自行编码通过hashmap来做少量数据的缓存,但是,如果结果可能随时间改变或者是希望存储的数据空间可控的话,自己实现这种数据结构还是有必要的。
Guava Cache继承了ConcurrentHashMap的思路,使用多个segments方式的细粒度锁,在保证线程安全的同时,支持高并发场景需求。Cache类似于Map,它是存储键值对的集合,不同的是它还需要处理evict、expire、dynamic load等算法逻辑,需要一些额外信息来实现这些操作。对此,根据面向对象思想,需要做方法与数据的关联封装。如图5所示cache的内存数据模型,可以看到,使用ReferenceEntry接口来封装一个键值对,而用ValueReference来封装Value值,之所以用Reference命令,是因为Cache要支持WeakReference Key和SoftReference、WeakReference value。
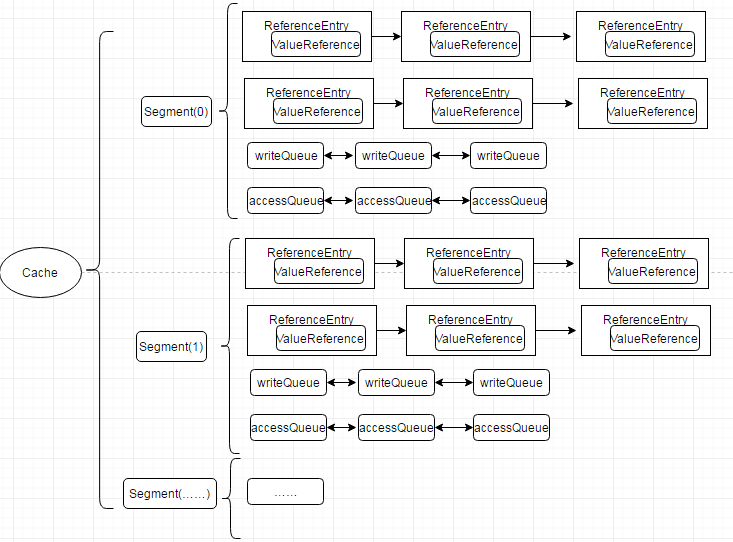
图5 Guava Cache数据结构图
ReferenceEntry是对一个键值对节点的抽象,它包含了key和值的ValueReference抽象类,Cache由多个Segment组成,而每个Segment包含一个ReferenceEntry数组,每个ReferenceEntry数组项都是一条ReferenceEntry链,且一个ReferenceEntry包含key、hash、valueReference、next字段。除了在ReferenceEntry数组项中组成的链,在一个Segment中,所有ReferenceEntry还组成access链(accessQueue)和write链(writeQueue)(后面会介绍链的作用)。ReferenceEntry可以是强引用类型的key,也可以WeakReference类型的key,为了减少内存使用量,还可以根据是否配置了expireAfterWrite、expireAfterAccess、maximumSize来决定是否需要write链和access链确定要创建的具体Reference:StrongEntry、StrongWriteEntry、StrongAccessEntry、StrongWriteAccessEntry等。
对于ValueReference,因为Cache支持强引用的Value、SoftReference Value以及WeakReference Value,因而它对应三个实现类:StrongValueReference、SoftValueReference、WeakValueReference。为了支持动态加载机制,它还有一个LoadingValueReference,在需要动态加载一个key的值时,先把该值封装在LoadingValueReference中,以表达该key对应的值已经在加载了,如果其他线程也要查询该key对应的值,就能得到该引用,并且等待改值加载完成,从而保证该值只被加载一次,在该值加载完成后,将LoadingValueReference替换成其他ValueReference类型。ValueReference对象中会保留对ReferenceEntry的引用,这是因为在Value因为WeakReference、SoftReference被回收时,需要使用其key将对应的项从Segment的table中移除。
WriteQueue和AccessQueue :为了实现最近最少使用算法,Guava Cache在Segment中添加了两条链:write链(writeQueue)和access链(accessQueue),这两条链都是一个双向链表,通过ReferenceEntry中的previousInWriteQueue、nextInWriteQueue和previousInAccessQueue、nextInAccessQueue链接而成,但是以Queue的形式表达。WriteQueue和AccessQueue都是自定义了offer、add(直接调用offer)、remove、poll等操作的逻辑,对offer(add)操作,如果是新加的节点,则直接加入到该链的结尾,如果是已存在的节点,则将该节点链接的链尾;对remove操作,直接从该链中移除该节点;对poll操作,将头节点的下一个节点移除,并返回。
了解了cache的整体数据结构后,再来看下针对缓存的相关操作就简单多了:
- Segment中的evict清除策略操作,是在每一次调用操作的开始和结束时触发清理工作,这样比一般的缓存另起线程监控清理相比,可以减少开销,但如果长时间没有调用方法的话,会导致不能及时的清理释放内存空间的问题。evict主要处理四个Queue:1. keyReferenceQueue;2. valueReferenceQueue;3. writeQueue;4. accessQueue。前两个queue是因为WeakReference、SoftReference被垃圾回收时加入的,清理时只需要遍历整个queue,将对应的项从LocalCache中移除即可,这里keyReferenceQueue存放ReferenceEntry,而valueReferenceQueue存放的是ValueReference,要从Cache中移除需要有key,因而ValueReference需要有对ReferenceEntry的引用,这个前面也提到过了。而对后面两个Queue,只需要检查是否配置了相应的expire时间,然后从头开始查找已经expire的Entry,将它们移除即可。
- Segment中的put操作:put操作相对比较简单,首先它需要获得锁,然后尝试做一些清理工作,接下来的逻辑类似ConcurrentHashMap中的rehash,查找位置并注入数据。需要说明的是当找到一个已存在的Entry时,需要先判断当前的ValueRefernece中的值事实上已经被回收了,因为它们可以是WeakReference、SoftReference类型,如果已经被回收了,则将新值写入。并且在每次更新时注册当前操作引起的移除事件,指定相应的原因:COLLECTED、REPLACED等,这些注册的事件在退出的时候统一调用Cache注册的RemovalListener,由于事件处理可能会有很长时间,因而这里将事件处理的逻辑在退出锁以后才做。最后,在更新已存在的Entry结束后都尝试着将那些已经expire的Entry移除。另外put操作中还需要更新writeQueue和accessQueue的语义正确性。
- Segment带CacheLoader的get操作:1. 先查找table中是否已存在没有被回收、也没有expire的entry,如果找到,并在CacheBuilder中配置了refreshAfterWrite,并且当前时间间隔已经操作这个事件,则重新加载值,否则,直接返回原有的值;2. 如果查找到的ValueReference是LoadingValueReference,则等待该LoadingValueReference加载结束,并返回加载的值;3. 如果没有找到entry,或者找到的entry的值为null,则加锁后,继续在table中查找已存在key对应的entry,如果找到并且对应的entry.isLoading()为true,则表示有另一个线程正在加载,因而等待那个线程加载完成,如果找到一个非null值,返回该值,否则创建一个LoadingValueReference,并调用loadSync加载相应的值,在加载完成后,将新加载的值更新到table中,即大部分情况下替换原来的LoadingValueReference。
Guava Cache提供Builder模式的CacheBuilder生成器来创建缓存的方式,十分方便,并且各个缓存参数的配置设置,类似于函数式编程的写法,可自行设置各类参数选型。它提供三种方式加载到缓存中。分别是:
- 在构建缓存的时候,使用build方法内部调用CacheLoader方法加载数据;
- callable 、callback方式加载数据;
- 使用粗暴直接的方式,直接Cache.put 加载数据,但自动加载是首选的,因为它可以更容易的推断所有缓存内容的一致性。
build生成器的两种方式都实现了一种逻辑:从缓存中取key的值,如果该值已经缓存过了则返回缓存中的值,如果没有缓存过可以通过某个方法来获取这个值,不同的地方在于cacheloader的定义比较宽泛,是针对整个cache定义的,可以认为是统一的根据key值load value的方法,而callable的方式较为灵活,允许你在get的时候指定load方法。使用示例如下:
1 | /** |
总体来看,Guava Cache基于ConcurrentHashMap的优秀设计借鉴,在高并发场景支持和线程安全上都有相应的改进策略,使用Reference引用命令,提升高并发下的数据……访问速度并保持了GC的可回收,有效节省空间;同时,write链和access链的设计,能更灵活、高效的实现多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等;编程式的build生成器管理,让使用者有更多的自由度,能够根据不同场景设置合适的模式。